Kubernetes Webhooks, Explained
Before the onset of the pandemic, I gave a talk at the Madison Cloud Native meetup titled “Aspect-Oriented Deployments with Kubernetes.” This blog post is a long-overdue follow up to that talk, but if you’re more of a visual person or if you’ve just stumbled across this post independently, I’ve included the video of my talk here. (This is extracted from a longer talk which can you still view here, wherein my portion starts at the 36:12 mark.)
At the time, documentation on Kubernetes webhooks was scarce and almost non-exsitent. Now there is much better documentation available, and I would recommend perusing their article on Dynamic Admission Control. But I still have some unique insights to share, so I’ll dive right into the nitty gritty details. I’ve broken this post up into a few sections.
What is Kubernetes?
To understand how webhooks work, first it’s necessary to explain a little bit of how Kubernetes works. Kubernetes is an open-source container orchestration platform and has become the gold standard in modern server deployment. When I began my software engineering career in 2008 as a PHP developer, I remember copying over PHP scripts onto bare metal web servers running Microsoft IIS. It was the best of times and the worst of times. It was certainly a very clunky way to handle deployments, as servers were treated more like pets than like cattle.
Kubernetes starts from the premise that your application must be containerized, using the Open Container Interface (standard) – the most well-known of which is Docker containers. Containerization fulfills the promise that Java set out to solve decades ago, ensuring that you can write your application once and then run it anywhere. Well, just as Java does still have the limitation that you can only run things where a JVM is installed, containers need a container runner installed, like Kubernetes.
Kubernetes allows you to define a number of different types of objects including pods, deployments, services, ingress, and more. A pod is the smallest, most concrete type of object in the Kubernetes ecosystem. A pod is simply a collection of one or more containers that runs on one of the Kubernetes nodes. Often this is a single container running indefinitely, like a web server, but it can also be a one-off script that runs to completion, or a combination of containers that work in tandem with each other.
There are a couple of higher-order objects that wrap the creation of pods with extra metadata, and fundamentally these are broken into two types: deployments and jobs. Deployments expect that the primary container will run forever, while jobs expect that the containers will terminate. Deployments automatically ensure that if a corresponding pod dies, Kubernetes will automatically spawn a replacement. And similarly with jobs, a pod that exits with a non-zero error code will be retried.
What are webhooks?
Kubernetes also defines two lesser-known object types called webhooks which affect the creation of pods: the ValidatingWebhookConfiguration
and the MutatingWebhookConfiguration. These are also sometimes referred to as Validating Admission webhooks and Mutating Admission webhooks,
respectively. When Kubernetes needs to create a pod, it first sends the definition (specification) of that pod to any registered Mutating
webhooks. Those webhooks (because it could be plural!) either respond with an indication that the pod spec should be changed or not.
Then, the potentially-updated pod definition is sent to any registered Validating webhooks, which in turn respond with a message to either
allow the pod to be created, or not. Here’s a simple diagram to illustrate.
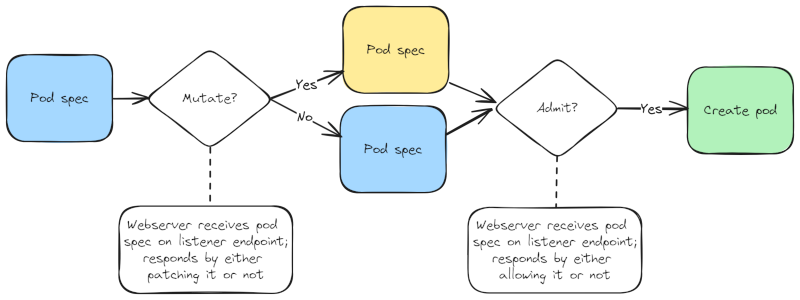
Now allow me to explain the details of this API contract. These two types of webhook objects (like many Kubernetes object types) largely serve as pointers to somewhere else, where the real magic happens. And the main crux of a webhook configuration object, whether it’s a validating or mutating type, is in a listener endpoint, inside of a custom web service. Thus it’s important to understand that in order to leverage webhooks, you first need to define your own web service. This service can be deployed within the same Kubernetes cluster, though it doesn’t strictly need to be (and in my talk I showcased an example of using an external AWS Lambda function as my webhook service).
So all the magic happens within your custom web service, while the webhook configuration objects defined in Kubernetes simply tells Kubernetes where to go. From the Kubernetes perspective, there are really only two inputs here: the type of webhook (implicit in the object type you choose), and the pointer to your web server endpoint. Your web server then needs to be sure to respond in a way that conforms to the Kubernetes API contract for the chosen type of webhook. And I find that the best way to understand this is by showing off exactly what that looks like.
In the case of a Validating Admission webhook, your custom listener would need to respond with something like this:
{
"response": {
"uid": "2441cee4-352b-11e9-85be-b8975a0ca30c",
"allowed": true
}
}
And in the case of a Mutating Admission webhook, your custom listener function might respond with something like this:
{
"response": {
"uid": "2441cee4-352b-11e9-85be-b8975a0ca30c",
"allowed": true,
"patch": "W3sib3AiOiJhZGQiLCJwYXRoIjoiL3NwZWMvdm9sdW1lcy8tIiwidmFsdWUiOnsibmFtZSI6ImVudmNvbmZpZy12b2x1bWUifX1d"
}
}
So at a glance, the contract appears pretty simple. Both associate a unique ID with the response, and both output a
Boolean flag called allowed. In the case of Validating Admission webhooks, this is all they do. In the case of
Mutating Admission webhooks, an additional field called patch is included, which as you can see appears to contain
some base64 encoded text. More on that in a minute.
From a high level, you can think of webhooks as functions that operate on your pods, before they launch.
The webhook endpoint will receive a payload that defines a pod Kubernetes is trying to create, and then
your endpoint will respond by saying first whether that operation should be allowed, and optionally if
that pod definition should be modified before being launched. (Side note: because both types require
allowed: true, the mutating webhook can do everything that a validating webhook can do.)
Recommended Reading
For the rest of this post, I’m going to assume that you already agree this is a good idea and dive further into the details. But if you want a more in-depth look at the concepts behind Kubernetes webhooks, let me recommend any of the following articles:
- Dynamic Admission Control from the official Kubernetes documentation
- Back to Basics: Kubernetes Admission Webhooks by Mina Omobonike
- Diving into Kubernetes MutatingAdmissionWebhook by Morven Cao
- Getting Started with Kubernetes Validating Admission Webhooks the FaaS Way by Kelsey Hightower
What is going on with that webhook API?
If you’re like me, you probably found it a bit confusing that the official standard has you return a JSON object which contains a base64 string. As I mentioned, when I first started looking at these 5 years ago, the documentation essentially did not exist. So I had to fire up some code I found from Banzai Cloud, detailed in this blog post, and reverse engineer what they were doing by substituting my own web server and logging the responses. And what I discovered was even wilder than I expected: the base64 string contained within the JSON response is just more JSON.

In the example I included in the last section, the base64 string actually decodes to this:
[
{
"op": "add",
"path": "/spec/volumes/-",
"value": {
"name": "envconfig-volume"
}
}
]
As you can see, that is simply a JSON list of objects. Why wasn’t that list just directly embedded as the patch
element in the parent response? Which came first, the chicken or the egg? How many licks to get to the Tootsie Roll
center of a Tootsie pop? There are some questions that just don’t have any real answers. We just need to accept
that this is the contract we have: the webhook returns JSON, with a base64 string representing a further nested
JSON list. Taking a closer look at that list, it is clear that each object contains three keys: op, path,
and value. As it turns out, this is part of the JSON Patch specification, which is codified in
RFC-6902. From the JSON Patch documentation:
JSON Patch is a format for describing changes to a JSON document. It can be used to avoid sending a whole document when only a part has changed.
For those who have worked with Kubernetes for any amount of time, you are surely familiar with the fact that K8s uses YAML as its format for defining objects. So why are we talking so much about JSON? Because, for all intents and purposes, JSON and YAML are basically isomorphic – meaning you can losslessly transform one into the other and back. And before you all come at me with pitchforks, I know that isn’t technically true. Technically, YAML is a superset of JSON. But again, in the most common use cases, they are effectively isomorphic.
A primer on JSON patch
The JSON Patch website itself already provides a very digestible explanation of JSON Patch, so if you’re seriously considering writing your own Mutating Webhook Controllers, I strongly recommend you read through their documentation. But I will cover some highlights here as well. Let me begin by breaking down those three keys which are present on all JSON Patch objects:
op- Operation, can be one of:add,remove,replacepath- The path to the specific JSON attribute that this operation will affectvalue- The new value (omitted when the operation isremove)
So that’s pretty straightforward: in order to mutate your pod spec definition, you will either add, remove,
or replace properties in the JSON document that gets translated from its original YAML definition. The path
convention has its own specification but is pretty easy to understand. The path always begins with / and
each nested element down is delimited by additional /s. When you’re targeting an element to change or remove,
you simply target it directly. And in the case of lists, you can separate the list indices with their index number
and another slash. Finally, when adding new items to a list, you should end your path with /- which is a special
syntax to indicate you’ll be appending an item.
So in the example I gave above (inside the base64 string), I had used /spec/volumes/- as the path. This assumes
that there is already a list defined at /spec/volumes. To make this a little more real, let me give an example
of a pod spec in YAML, before and after mutation. Again, we will refer back to the example patch operation given
earlier which was this: {"op":"add","path":"/spec/volumes/-","value":{"name":"envconfig-volume"}}.
Before
apiVerison: v1
kind: Pod
metadata:
name: mycoolwebapp
spec:
containers:
- name: mycoolwebapp
image: artifacts.server.com/docker/mycoolwebapp:latest
volumes:
- name: test-volume
After
apiVerison: v1
kind: Pod
metadata:
name: mycoolwebapp
spec:
containers:
- name: mycoolwebapp
image: artifacts.server.com/docker/mycoolwebapp:latest
volumes:
- name: test-volume
- name: envconfig-volume
The importance of testing
I hope you can already start to see how powerful Mutating Admission webhooks can be. They receive the pod spec definition (translated into JSON), parse it, and then make decisions on how to modify it. They relay those decisions by returning a list of JSON patch operations. But I also want to caution that this is also a very dangerous tool. In my talk at the meetup group, I quoted the famous Spiderman platitude that “with great power comes great responsibility.” This is because your webhook function needs to be absolutely rock-solid, because if it fails or produces bad JSON, the result will be that your pods won’t launch. So if you are someone who hardly ever writes unit tests, you should start writing them specifically for your webhook function. And even if you do write tests, when it comes to webhooks, write more. I cannot stress enough how good your test coverage on your webhook function should be.
Let’s consider a quick example to illustrate why good testing is so important. In my previous example, I patched the
/spec/volumes list by adding an element to it. But what would have happened if the original pod specification hadn’t
contained a property at /spec/volumes to begin with? (In other words, what if no volumes were defined?) Then trying to
add an element under /spec/volumes/- would have resulted in a failure, and the intended pod would not have been
launched. So the webhook code needs to be resilient enough to check for whether the property exists, and then conditionally
return either add to /spec/volumes/- or perform a replace on /spec/volumes instead.
Are you starting to understand why I’m saying that unit tests are so important?
How the pod spec is transmitted
So far I’ve focused entirely on the output of your function, and while I’ve made cursory allusions to the fact that the
pod spec is transmitted, I haven’t yet showcased that. So let’s dive deeper. Technically what gets transmitted to your
webhook listener endpoint (in the POST body) is an AdmissionReview object. At the end of the day, this is just another
Kubernetes object type. But instead of transmitting it as YAML, it is sent to your endpoint as a JSON object. I have included
below a highly truncated version of an AdmissionReview object that was actually sent to one of my webhook endpoints:
{
"kind": "AdmissionReview",
"apiVersion": "admission.k8s.io/v1beta1",
"request": {
"uid": "2441cee4-352b-11e9-85be-b8975a0ca30c",
"operation": "CREATE",
"object": {
"kind": "Pod",
"apiVersion": "v1",
"metadata": {
"namespace": "default",
"annotations": {
"consul.myserver.com/kv": "jobs/my_job",
"vault.myserver.com/role": "my-job",
"vault.myserver.com/secret": "jobs/my_job"
}
},
"spec": {
"containers": [
{
"name": "my-job",
"image": "artifacts.myserver.com/docker/my-job:0.27.0",
"imagePullPolicy": "Always"
}
]
},
}
}
}
I have truncated this object significantly, and you can refer to this gist if you want to see the full object.
In the full object, the metadata and spec keys contain a lot more keys than what I have shown here.
So let me focus on the important points.
Earlier when I was explaining the response contract, I included a field named uid under the response key.
That value needs to be copied from the original request, shown above under the /request/uid path. And then secondly, you’ll notice
that there is a key under /request/object. This is the JSON representation of your Kubernetes object that I was talking about earlier.
You can see that this example features a Pod object, but in theory this could be a Service, a Deployment, or any other Kubernetes resource. The specific resource upon which your webhook receives callback events can be configured when creating the webhook object to begin with. But as this article is already long, I’ll continue to focus just on the Pod use case and leave extrapolation to how this can be applied to other types as an exercise for the reader.
Annotations and AOP
In my talk at the meetup group four years ago (which was titled “Aspect-Oriented Deployments with Kubernetes”), I tied a few concepts together. From Wikipedia:
Aspect-oriented programming (AOP) is a programming paradigm that aims to increase modularity by allowing the separation of cross-cutting concerns.
The specific webhook example I showcased inspected the pod spec to determine whether or not certain annotations were present, and when so it would mutate the pod definition to facilitate an automatic connection to Hashicorp Vault in order to provide secure dependency injection. One reason for doing this at the time was that Role-Based Access Control (RBAC) had not been fully implemented in Kubernetes yet, so leaking secrets was a real concern. Nowadays RBAC is a mature and stable part of the Kubernetes ecosystem, so there is much less concern over using K8s secrets – thereby making the whole purpose of my particular webhook application somewhat moot. But the underlying principles still teach elegant lessons in engineering principles like separation of concern.
One of the most popular web frameworks in Java is Spring Boot, which has a framework for handling
authentication called Spring Security. Spring Security provides an excellent object lesson in
Aspect-Oriented Programming. For example, using this framework you could define a method called
getToken and apply one of Spring Security’s built-in annotations such as @Secured to ensure
that the method can only be invoked when the current user has a specified role.
@Secured("ROLE_VIEWER")
public String getToken() {
SecurityContext securityContext = SecurityContextHolder.getContext();
String username = securityContext.getAuthentication().getName();
return userService.getTokenForUsername(username);
}
This allows developers to write methods that focus on their core functionality, without worrying about the details of cross-cutting concerns such as authentication and authorization, thereby providing effective modularity. Programming languages like Java provide a system where the annotations ultimately execute code. Even Python (where annotations are actually called decorators) does the same. But Kubernetes is not a programming language; it’s an orchestration framework. And the objects in Kubernetes are all declarative, much like HTML, meaning Kubernetes annotations don’t actually do anything. They simply are a piece of textual metadata on a pod (or another object).
But webhooks are the missing link that allow you to take full advantage of annotations and AOP. You have full freedom to write your webhooks in whatever way you want, to respond to whatever conditions exist on a pod spec that you like. But I strongly advise that when writing custom Kubernetes webhooks, you focus entirely on which annotations are present (or not) as the mechanism for deciding whether to patch your objects. Strictly speaking, you don’t have to do this. I could envision someone writing a webhook to deny admission on pods who have memory requests above a certain limit. (Though it is probably still better to simply rely on the internals of Kubernetes to handle that.) Or I could envision someone using a webhook to automatically rewrite container image paths from an old container registry to a new one. (Though it would be better to simply update your Helm charts with the new registry.) By responding to the presence of custom annotations, you will build resilient and maintainable applications that are useful and conform to a tried-and-true architecture pattern.
Miscellaneous Pitfalls
After my talk, a very nice man in the audience came up and asked if I had any specific challenges in building my webhook application that I may have left out of the talk. In the moment, I couldn’t think of anything, but on later reflection it was immediately obvious that there is one major issue I had glossed over at the meetup group. That major issue again relates to the fact that Kubernetes objects, being entirely declarative, are dumb. They don’t go out of their way to tell you much, only what gets typed up and nothing more. But any time default values are inherited, they are not reflected in the specification sent to your webhook.
In my particular application, this was a problem because my webhook application was responsible for
dynamically rewriting the entrypoint of container images by prefixing an invocation of a custom
binary application. So if the original entrypoint was python main.py, the mutated form would be
envconfig -- python main.py. The problem is that not every pod spec will tell you what the
original entrypoint is at all. In the vast majority of cases, the entrypoint is omitted in the
deployment or job definitions because containers are meant to launch from their entrypoint by
design. Typically, people will only specify the entrypoint in K8s pod specifications when they
are overriding it with something custom. Thus, when the webhook is handed an AdmissionReview
object containing the pod spec, no entrypoint will be present almost all of the time.
The naive way to handle this problem would be to have your webhook server make a subprocess call
to Docker to run docker inspect on the provided image, and thereby look up the entrypoint
(as well as other information) about the container image. But I hopefully don’t need to elaborate
on just how gross that would be. Fortunately, I came across an article titled Inspecting Docker images without pulling them
which discusses the underlying container registry API behind Dockerhub, namely registry.docker.io.
This gave me the adequate hints needed to code up some simple web requests to be able to pull
the metadata about containers without needing to install Docker and make procedure calls.
However, while that code worked fine for Dockerhub, it needed to be adapted for Amazon ECR, and further adapted for Artifactory. With the proliferation of other container registry offerings such as Gitlab, Nexus, Google Artifact Registry, and so on, you might need to handle authentication differently for all of them. At the time, we were leveraging Artifactory and I confess there are caveats to their API that I still, to this day, do not understand. But I did want to provide a quick distillation of the article I mentioned into some simple Python code for others’ benefit.
from urllib.parse import urlparse
import requests
def get_docker_registry_credentials(image_name):
response = requests.get("https://auth.docker.io/token", params={
"service": "registry.docker.io",
"scope": f"repository:{image_name}:pull",
})
response.raise_for_status()
token_wrapper = response.json()
return "Bearer " + token_wrapper.token
def get_container_config(image):
parsed = urlparse("//" + image)
if not parsed.path:
hostname = "registry-1.docker.io"
components = image.split(":")
else:
hostname = parsed.hostname
components = parsed.path.split(":")
if len(components) > 1:
image_name = components[0].strip("/")
image_tag = components[1]
else:
image_name = parsed.path
image_tag = "latest"
if hostname == "registry-1.docker.io" and "/" not in image_name:
image_name = "library/" + image_name
headers = {"Accept": "application/vnd.docker.distribution.manifest.v2+json"}
if hostname == "registry-1.docker.io":
headers["Authorization"] = get_docker_registry_credentials(image_name)
elif hostname == "your.container.registry":
...
else:
raise NotImplementedError(f"Unknown container registry: {hostname}")
url = f"https://{hostname}/v2/{image_name}/manifests/{image_tag}"
response = requests.get(url, headers=headers)
response.raise_for_status()
manifests = response.json()
digest = manifests.get("config", {}).get("digest")
if not digest:
raise KeyError(f"No config digest found for image: {image_name}")
url = f"https://{hostname}/v2/{image_name}/blobs/{digest}"
response = requests.get(url)
response.raise_for_status()
metadata = response.json()
return metadata.get("config", {})
That code snippet allows me to call get_container_config() on any arbitrary Docker image.
As you can see, I left off custom logic for other container registries, but it’s generally
not that difficult to provide them – you usually just have to add an Authorization header.
With that in mind, there are other default values that do not get propagated into the AdmissionReview object. Again, any time a property is omitted from the K8s object, the default value will be used, but your webhook will need some way of determining what that default value is.
Conclusion
I hope this post has been instructive and useful. Are you already using principles from AOP in your Kubernetes deployments? Or have you been leveraging webhooks in another way? Also, do you know of better ways to cope with the pitfalls from needing to inspect container images from Docker registries? (Or have you had to deal with authentication issues from private ones?) Let me know in the comments if you have any lingering questions, or go ahead and share what creative uses for Kubernetes webhooks you’ve come up with!